In this lecture we continue with our discussion of SDEs and how to manipulate them. Specifically, we will look how we can describe the evolution of the probability density of an SDE via the Fokker-PLanck Equation, how we can reverse SDEs via Nelsons Duality Formula and how we can use these ideas to build generative models such as score-based or flow matching models.
In the first lecture we saw that while the solution of an ODE is just a deterministic function, the solution of an SDE is a stochastic process. We can describe this process by the SDE solution, but as a stocastic process it also has properties like a probability distribution and statistics. In this first part, we will therefore look at the Fokker-Planck Equation (FPE), which describes the evolution of the probability density of an SDE and look at the FPE for some common SDEs.
Definition: The Fokker-Planck Equation (FPE) describes the evolution of the probability density of an SDE. For a general SDE of the form dXt=μ(Xt,t)dt+σ(Xt,t)dWt, it is given by
where p(x,t) is the probability density of the SDE at time t and x and D(x,t)=2σ2(Xt,t) is defined as the diffusion coefficient.
To emphasise that there is a separate probability density for each time step, we will sometimes write the probability density p(x,t) as pt(x) instead, where x is the value of the SDE at time t. The FPE describes how this probability density evolves over time.
We will first derive the FPE for the special case of Brownian motion, then derive this general formula here and then look at the FPE for some common SDEs.
For completeness, the FPE for a general SDE of the form dXt=μ(Xt,t)dt+σ(Xt,t)dWt is given by ∂tp(x,t)=−i=1∑d∂xi[μi(xi,t)p(x,t)]+i,j=1∑N∂xi,xj[σσij(x,t)p(x,t)]
1.1 FPE for Brownian Motion
Let’s start with the special case of Brownian motion, a stochastic process we discussed in the first lecture. For generality, let us denote the stochastic process as Xt, i.e. setting Xt=Bt where Bt is the Brownian motion.
Our SDE for Brownian motion is therefore (surprise, surprise) given by dXt=dBt.
Let us look at a twice continously differentiable, arbitrary function f(Xt) with compact support and apply Ito’s lemma to it. We get df(Xt)E[df(Xt)]dtdE[f(Xt)]dtd∫−∞∞f(x)p(x,t)dx∫−∞∞f(x)∂t∂p(x,t)dx∫−∞∞f(x)∂t∂p(x,t)−21∂x2∂2p(x,t)f(x)dx∂t∂p(x,t)−21∂x2∂2p(x,t)=∂tf(Xt)dt+∂xf(Xt)dXt+21∂xxf(Xt)(dXt)2=∂xf(Xt)dBt+21∂xxf(Xt)dt=E[∂xf(Xt)dBt+21∂xxf(Xt)dt]∣E[dBt]=0=21E[∂xxf(Xt)]dt∣use dom. convergence theorem=21E[∂xxf(Xt)]∣rewrite E and write ∂xxf(x)=fxx(x)=21∫−∞∞fxx(x)p(x,t)dx∣integrate RHS by parts=21[fxx(x)p(x,t)∣∣x=−∞x=∞−∫−∞∞fx(x)∂x∂p(x,t)dx]∣compact support: first term = 0=−21∫−∞∞fx(x)∂x∂p(x,t)dx∣integrate RHS by parts again=−21[fx(x)∂x∂p(x,t)∣∣x=−∞x=∞−∫−∞∞f(x)∂x2∂2p(x,t)dx]∣compact support: first term = 0=21∫−∞∞f(x)∂x2∂2p(x,t)dx∣pull derivative inside integral on LHS=21∫−∞∞f(x)∂x2∂2p(x,t)dx∣regroup terms=0∣f is arbitrary=0
This is the FPE for Brownian motion and known as the Diffusion equation. It looks very similar to the heat equation and can be derived from the general FPE formula by setting μ(x,t)=0 and σ(x,t)=1.
1.2 FPE for General SDEs
Now let’s consider how we derive the FPE for a general SDE. The procedure is very similar to the derivation for Brownian motion, but we have to be a bit more careful since now we have a drift term μ(x,t) and a non-constant diffusion term σ(x,t).
1.3 FPE for GBM and OU
We can now use the general FPE formula to derive the FPE for some common SDEs. We will not derive them here from scratch but start from the formula for general SDEs from the last section.
For the zero-centered Ornstien-Uhlenbeck process dXt=−θXtdt+σdBt, we have μ(x,t)=−θx and σ(x,t)=σ. Plugging this into the general FPE formula, we get ∂t∂p(x,t)=−θ∂x∂xp(x,t)+21σ2∂x2∂2p(x,t)
For the Geometric Brownian Motion dXt=μXtdt+σXtdBt, we have μ(x,t)=μx and σ(x,t)=σx. Plugging this into the general FPE formula, we get ∂t∂p(x,t)=−μ∂x∂xp(x,t)+21σ2∂x2∂2p(x,t)x2
2. Time Reversal - Nelson, Anderson and co
In the first lecture we saw that the solution of an SDE is a stochastic process. We can describe this process by the SDE solution, but as a stocastic process it also has properties like a probability distribution and statistics. We now looked at the Fokker-Planck Equation (FPE), which describes the evolution of the probability density of an SDE.
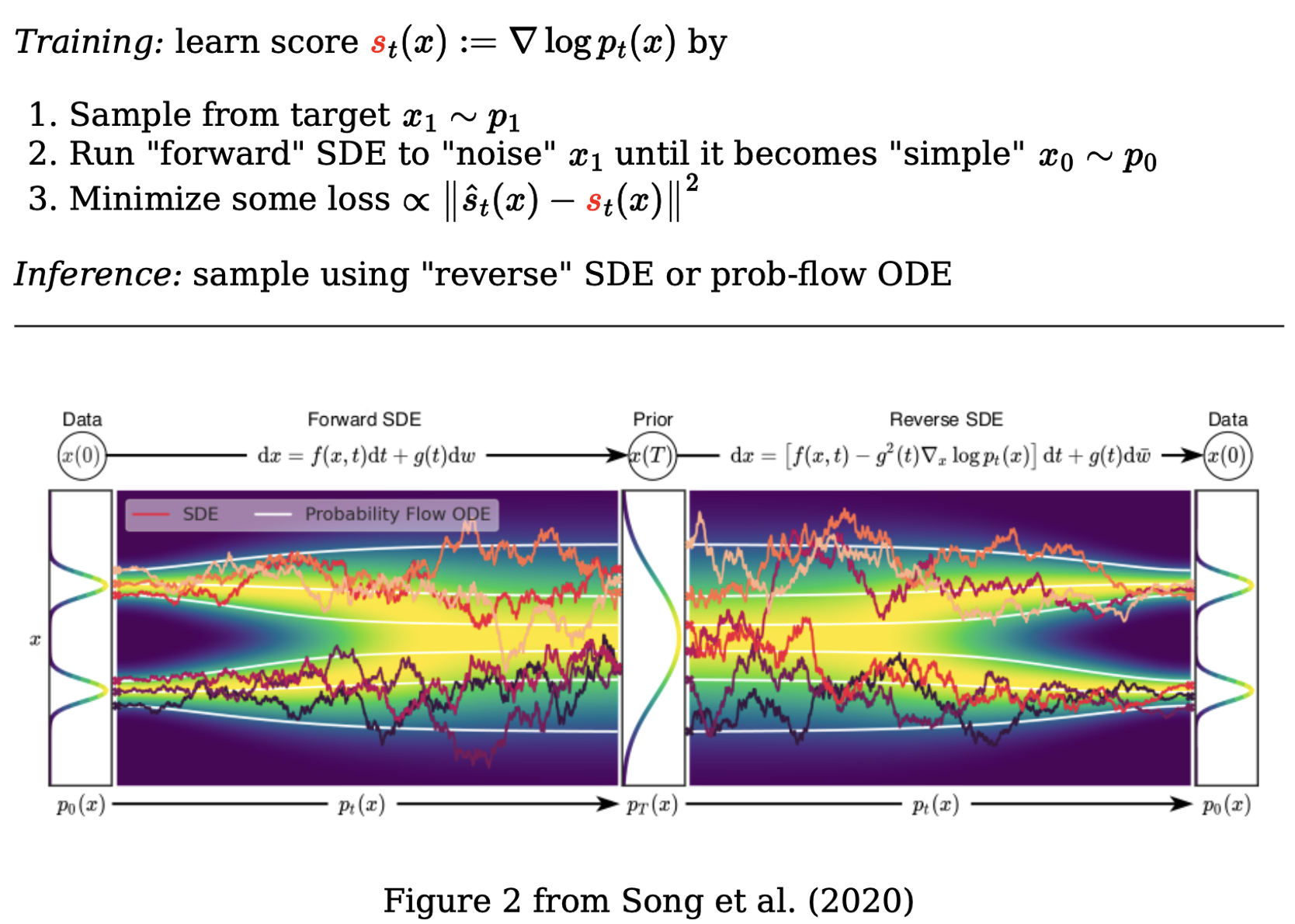
This is all very nice, but the key insight of diffusion models is that we can reverse an SDE. The results leading to this conclusion are all decades old (see Anderson 1982, Haussmann & Pardoux 1986, Nelson 1967 or Foellmer 1987), but have only recently been applied in the area of generative modelling. In this section we will look at how we can reverse an SDE and what this means for the FPE.
2.1 A discrete time “heuristic” sketch
Let’s say we have a SDE we want to reverse and know its FPE. We can see the probability densities evolving over time as a joint distribution of the values at all times. If we consider two time points, t and t+δ, we can factor the joint distribution into conditional probabilities in two ways via the chain rule of probability: pt,t+δ(x,y)=pt+δ∣t(y∣x)pt(x)=pt∣t+δ(x∣y)pt+δ(y)
where we denote a random variable at time t as x and a random variable at time t+δ as y.
This is exactly true when p is the exact solution of the FPE and therefore the different conditional probabilities are the exact transition densities of our SDE.
However, let us now do a small hack: we discretise time via the Euler-Maruyama method and approximate the transition densities via the Euler-Maruyama transition densities. As a reminder, an Euler-Maruyama discretisation step for our typical SDE dXt=μ(t,Xt)dt+σ(t,Xt)dWt after partitioning it into n discrete intervals looks like Xn+1=Xn+μ(Xn,n)δt+σ(Xn,n)δWn
If we assume this discretisation, the transition density equality we wrote down above is not valid anymore except for the limit δ→0. In this approximation, the forward transition density is aGaussian that depends on the drift and diffusion term in the following way: pt+δ∣t(y∣x)=N(y∣x+f+(x)δ,δσ2(x))
where we denote the drift term at time t as f+(x)=μ(x,t) and ignore the time dependency of the drift and diffusion terms for simplicity.
We now want to get an expression for the reverse transition density pt∣t+δ(x∣y). Rearranging the chain rule decomposition above, we get pt∣t+δ(x∣y)=pt+δ∣t(y∣x)pt+δ(y)pt(x)
We can now use Taylor’s theorem to expand the marginal densities pt around y. We expand not pt directly, but exp(logpt), since this is easier to work with. This results in pt∣t+δ(x∣y)=pt+δ∣t(y∣x)pt+δ(y)pt(y)e(x−y)T∇ylnpt(y)+O(δ2)
If we now make a Lipschitz assumption of the form ∣lnpt(x)−lnps(x)∣=O(∣t−s∣2), we can absorb the ratio of the marginal densities into the O(δ2) term and get pt∣t+δ(x∣y)=pt+δ∣t(y∣x)e(x−y)T∇ylnpt(y)+O(δ2)
We can now insert our Euler-Maruyama transition density for pt+δ∣t(y∣x), regroup the terms and complete the square to yield pt∣t+δ(x∣y)=N(y∣x+f+(x)δ,δσ2(x))e(x−y)T∇ylnpt(y)+O(δ2)=e(x−y)T∇ylnpt(y)+O(δ2)=2πδd/2σde−σ2δ∥x−(y−f+(y)δ+σ2∇ylnpt(y)δ)∥+O(δ2)
This is the reverse transition density for the Euler-Maruyama discretisation of the following SDE: dXt=[−f+(Xt,T−t)+σ2∇XtlnpT−t(Xt)]dt+σdWt
We can see that this SDE is very similar to the original SDE, but with the drift term f+ replaced by −f+ and an additional term σ2∇XtlnpT−t(Xt) added. We can define this sum as the drift term f− of the reverse SDE and get a formula via this that relates the forward and reverse drift with each other: f−(x,t)+−f+(x,T−t)=σ2∇xlnpT−t(x)
2.2 Anderson’s Derivation
In the previous section we saw a “heuristic” derivation of the reverse transition density. In this section we will look at the more rigorous derivation of the reverse transition density that Anderson took in his paper from 1982. We will not look at the full derivation that spans section 3 and 4, but will focus on the “simpler” derivation in section 5 that they came up with first, but that did not include all the results they present in the paper (for us it is enough though).
Let us stort again with our general SDE dXt=μ(Xt,t)dt+σ(Xt,t)dWt and the FPE for this SDE: ∂t∂pt(xt)=−∂xt∂[μ(xt)pt(xt)]+21∂x2∂2[σ2(xt)pt(xt)]
The FPE is also known as the forward Kolmogorov equation and describes the evolution of the probability density of the SDE.
However, there is also a backward Kolmogorov equation that is defined as −∂t∂ps(xs∣xt)=μ(xt)∂xt∂[ps(xs∣xt)]+21σ2(xt)∂x2∂2[ps(xs∣xt)]
where s≥t, i.e s=t+δ from our previous section. Note that we condtion on the value of the SDE at time t and not on the value of the SDE at time s and that we also differentiate with respect to xt and not xs. This is a bit confusing at first, but we can think of it in the following way: the equation describes how the probability density of the SDE at time s evolves if we change the value of xt at time t. However, we do not know the corresponding drift and diffusion terms to form the reverse SDE. Anderson now used a similar chain rule factorisation to what we did in our heuristic sketch to derive these terms. ps(xs,xt)−∂t∂ps(xs,xt)−∂t∂ps(xs,xt)=ps(xs∣xt)pt(xt)∣take derivative and *(-1)=−∂t∂[ps(xs∣xt)pt(xt)]∣product rule=−∂t∂[ps(xs∣xt)]pt(xt)−ps(xs∣xt)∂t∂[pt(xt)]
We can now insert the backward Kolmogorov equation into the first term on the RHS and the forward Kolmogorov equation into the second term on the RHS to get −∂t∂[ps(xs∣xt)]pt(xt)−ps(xs∣xt)∂t∂[pt(xt)]=(μ(xt)∂xt∂[ps(xs∣xt)]+21σ2(xt)∂xt2∂2[ps(xs∣xt)])pt(xt)+ps(xs∣xt)(∂xt∂[μ(xt)pt(xt)]−21∂xt2∂2[σ2(xt)pt(xt)])
We can now evaluate the derivatives for the KFE and KBE to insert them back into this equation.
For the KBE, we get ∂xt∂[ps(xs∣xt)]=∂xt∂[pt(xt)ps(xs,xt)]∣quotient rule=pt2(xt)∂xt∂[p(xs,xt)]pt(xt)−p(xs,xt)∂xt∂[pt(xt)]∣split nominator=pt(xt)∂xt∂[p(xs,xt)]−pt2(xt)p(xs,xt)∂xt∂[pt(xt)]
Now we can do the same for the two derivatives of products in the KFE terms: ∂xt∂[μ(xt)pt(xt)]∂xt2∂2[σ2(xt)pt(xt)]=∂xt∂[μ(xt)]pt(xt)+μ(xt)∂xt∂[pt(xt)]=∂xt2∂2[σ2(xt)]pt(xt)+2∂xt∂[σ2(xt)]∂xt∂[pt(xt)]+σ2(xt)∂xt2∂2[pt(xt)]
Substituting these derivatives back into the equation above, we get −∂t∂[ps(xs,xt)]=−∂t∂[ps(xs∣xt)]pt(xt)−ps(xs∣xt)∂t∂[pt(xt)]=(μ(xt)∂xt∂[ps(xs∣xt)]+21σ2(xt)∂xt2∂2[ps(xs∣xt)])pt(xt)+ps(xs∣xt)(∂xt∂[μ(xt)pt(xt)]−21∂xt2∂2[σ2(xt)pt(xt)])∣plug in derivatives=μ(xt)(pt(xt)∂xt∂[p(xs,xt)]−pt2(xt)p(xs,xt)∂xt∂[pt(xt)])pt(xt)+21σ2(xt)∂xt2∂2[ps(xs∣xt)]pt(xt)+ps(xs∣xt)∂xt∂[μ(xt)]pt(xt)+ps(xs∣xt)μ(xt)∂xt∂[pt(xt)]−21ps(xs∣xt)∂xt2∂2[σ2(xt)pt(xt)]∣fraction=μ(xt)(∂xt∂[p(xs,xt)]−pt(xt)p(xs,xt)∂xt∂[pt(xt)])+21σ2(xt)∂xt2∂2[ps(xs∣xt)]pt(xt)+ps(xs∣xt)∂xt∂[μ(xt)]pt(xt)+ps(xs∣xt)μ(xt)∂xt∂[pt(xt)]−21ps(xs∣xt)∂xt2∂2[σ2(xt)pt(xt)]∣Bayes=μ(xt)(∂xt∂[p(xs,xt)]−ps(xs∣xt)∂xt∂[pt(xt)])+21σ2(xt)∂xt2∂2[ps(xs∣xt)]pt(xt)+p(xs,xt)∂xt∂[μ(xt)]+ps(xs∣xt)μ(xt)∂xt∂[pt(xt)]−21ps(xs∣xt)∂xt2∂2[σ2(xt)pt(xt)]∣cancel terms=μ(xt)∂xt∂[p(xs,xt)]+p(xs,xt)∂xt∂[μ(xt)]+21σ2(xt)∂xt2∂2[ps(xs∣xt)]pt(xt)−21ps(xs∣xt)∂xt2∂2[σ2(xt)pt(xt)]∣product rule=∂xt∂[μ(xt)p(xs,xt)]+21σ2(xt)∂xt2∂2[ps(xs∣xt)]pt(xt)−21ps(xs∣xt)∂xt2∂2[σ2(xt)pt(xt)]
Among all this algebra, remember that what we want is get a FPE that tells us the equivalent reverse SDE terms (drift and diffusion term). We already have a first derivative ∂xt∂ that looks like a similar term in the FPE, but we still need to work with the rest in order to get a proper second order derivative term that matches the FPE.
To do this, we can see that the last two terms can be generated by the product rule of the following equation: ===21∂xt2[p(xs,xt)σ2(xt)]21∂xt2[p(xs∣xt)p(xt)σ2(xt)]21∂xt2p(xs∣xt)p(xt)σ2(xt)+∂xt[p(xt)σ2(xt)]∂xtp(xs∣xt)+21∂xt2[p(xt)σ2(xt)]p(xs∣xt)(1)21σ2(xt)∂xt2p(xs∣xt)p(xt)+∂xt[p(xt)σ2(xt)]∂xtp(xs∣xt)+(2)21p(xs∣xt)∂xt2[p(xt)σ2(xt)]
Term (1) and (2) are exactly the terms we need for the FPE. After completing the square with the center term, we can use exactly this equation to simplify our current expression: −∂tp(xs,xt)=====∂xt[μ(xt)p(xs,xt)]+21σ2(xt)∂xt2p(xs∣xt)p(xt)−21p(xs∣xt)∂xt2[σ2(xt)p(xt)]∂xt[μ(xt)p(xs,xt)]+21σ2(xt)p(xt)∂xt2p(xs∣xt)−21X=−X+21X−21p(xs∣xt)∂xt2[σ2(xt)p(xt)]complete the square±∂xtp(xs∣xt)∂xt[p(xt)σ2(xt)]∂xt[μ(xt)p(xs,xt)]+21σ2(xt)∂xt2p(xs∣xt)p(xt)−21X=−X+21X−p(xs∣xt)∂xt2[σ2(xt)p(xt)]+21p(xs∣xt)∂xt2[σ2(xt)p(xt)]±∂xtp(xs∣xt)∂xt[p(xt)σ2(xt)]∂xt[μ(xt)p(xs,xt)]+21∂xt2[p(xs∣xt)p(xt)σ2(xt)]−∂xt[p(xs∣xt)∂xt[σ2(xt)p(xt)]] (product rule) −p(xs∣xt)∂xt2[σ2(xt)p(xt)]−∂xtp(xs∣xt)∂xt[p(xt)σ2(xt)]∂xt[μ(xt)p(xs,xt)]+21∂xt2[p(xs,xt)σ2(xt)]−∂xt[p(xs∣xt)∂xt[σ2(xt)p(xt)]].
To make this look like a FPE now, we just need to combine the conditional and joint probability terms in the first order derivatives: −∂tp(xs,xt)===∂xt[μ(xt)p(xs,xt)−p(xs∣xt)∂xt[σ2(xt)p(xt)]]+21∂xt2[p(xs,xt)σ2(xt)]∂xt[p(xs,xt)(μ(xt)−p(xt)1∂xt[σ2(xt)p(xt)])]+21∂xt2[p(xs,xt)σ2(xt)]−∂xt[p(xs,xt)(−μ(xt)+p(xt)1∂xt[σ2(xt)p(xt)])]+21∂xt2[p(xs,xt)σ2(xt)]
We can see that this equation looks like a FPE/FKE. However, it still involves the joint density p(xs,xt), but we want it to only consist of the conditional and marginal densities. To do this, we can marginalise over xs via Leibniz’ rule to get −∂tp(xt)=−∂xt[p(xt)(−μ(xt)+p(xt)1∂xt[σ2(xt)p(xt)])]+21∂xt2[p(xt)σ2(xt)]
We can now use τ=T−t as time reversal to get a FPE for the reverse SDE: −∂tp(xt)=∂τp(xT−τ)=∂xT−τ[p(xT−τ)(μ(xT−τ)+p(xT−τ)1∂xT−τ[σ2(xT−τ)p(xT−τ)])]+21∂xT−τ2[p(xT−τ)σ2(xT−τ)]
We can now use this FPE to get the corresponding reverse SDE that can be solved backward in time: dXt=[−μ(xT−τ)+p(xT−τ)1∂xT−τ[σ2(xT−τ)p(xT−τ)]]dτ+σ(xT−τ)dW~t
where W~t is a reverse Brownian motion that flows backward in time.
We can again simplify this by assuming a scalar diffusion term and no dependency on xT−τ to get dXt=[−μ(xT−τ)+p(xT−τ)1σ2∂xT−τlogp(xT−τ)]dτ+σ(xT−τ)dW~t∣cancel p(xT−τ)dXt=[−μ(xT−τ)+σ2∂xT−τlogp(xT−τ)]dτ+σ(xT−τ)dW~t∣log-derivative trickdXt=[−μ(xT−τ)+σ2∂xT−τlogp(xT−τ)]dτ+σ(xT−τ)dW~t∣reverse time
We can see that similarly to our heuristic derivation, the reverse SDE contains the score term ∂xT−τlogp(xT−τ), which we can also write as ∂xtlogp(xt) since τ=T−t.
Here we see a small but important difference between the formulation of the reverse-time SDE in our heuristic treatment and in the derivation by Anderson. It coincides with different conventions of how to represent time reversals.
We can choose to “turn around” at time T and run our SDE in a “forward” manner, but with the time t running backwards. This is the convention we used in our heuristic derivation and the one that is used in e.g. De Bortoli 2021. In this case, the reverse SDE is given by
dXt=f−(Xt,t)dt+σdWt
An alternative is not to turn around at time T, but “run backwards” from time T, i.e. formulating the SDE using a reversed Brownian motion dW~t. This is the convention that Anderson used in his derivation and the one that is used in e.g. Song et al. 2021. In this case, the reverse SDE is given by
dXt=f−(X~t,t)dt+σdW~t
where X~t and W~t are the reverse SDE and Brownian motion, respectively.
3. Score-based modelling via SDEs
How do we now use this time-reversal formalism for generative modelling? To understand that, let us shortly discuss what score matching is.
3.1 From score matching to denoising score matching
When we train a generative model, we want to learn a probability density pθ(x) that matches the true data distribution pdata(x). We can do this by maximising the log-likelihood of the data under the model: θmaxEx∼pdatalogpθ(x)
However, this requires pθ(x) to be normalised, which is often intractable. There are many ways around this limitation, for example restricted model architectures in autoregressive models or approximating this constant via variational inference in VAEs. Here, we use the score function ∇xlogpθ(x) to learn the model. The score function is the gradient of the log-probability density and can be seen as a vector field that points in the direction of the steepest ascent of the density. We see tat this allows us to learn the model without having to normalise the density by the normalisation constant Zθ: sθ(x)=∇xlogpθ(x)=∇xlog(Zθfθ(x))=∇xlogfθ(x)−=0∇xlogZθ=∇xlogfθ(x)
We can then use this score function to learn the model by minimising the following loss function: Ep(x)[∥∇xlogp(x)−sθ(x)∥22]
There is a problem, though: we do not know the ground truth score function ∇xlogpdata(x), so we cannot directly minimise this loss.
However, we can use Score matching to minimise this loss without requiring access to the ground truth score function. There are different variants to score matching to make it more efficient/practical. We are not going into detail about the derivation and variants of score matching; if you want to understand more about the background, however, the papers from Aapo Hyvärinen are an excellent resoruce.
Here, we will focus on denoising score matching, where the idea is to add a bit of noise to each data point to smooth the data distribution and allow better score estimates. If we think of the noise addition in multiple (in fact infinitely many) steps, we can think of this noising process as an SDE (in practice an OU process is often used). We can then use the reverse SDE to get the corresponding reverse-time SDE that we can use to generate samples.
As you remember, the term that appeared in the reverse SDE was exactly our score function, ∇xlogp(x). To learn this, we use a training objective where we weight the Fisher divergence terms of all the different time points with a weighting function λ(t): Et∈U(0,T)Ept(x)[λ(t)∥∇xlogpt(x,t)−sθ(x,t)∥22]
where U(0,T) is a uniform distribution over the interval [0,T].
This loss allows us to train practical score-based models (also called denoising diffusion probabilistic models, DDPMs) that can be used to generate samples. It also allows us to make some important connections between our training objective and maximum likelihood training/KL divergence minimisation: KL(p0(x)∥pθ(x))≤2TEt∈U(0,T)Ept(x)[λ(t)∥∇xlogpt(x)−sθ(x,t)∥22]+KL(pT∥π)
3.2 Closed-from transition densities for fast training
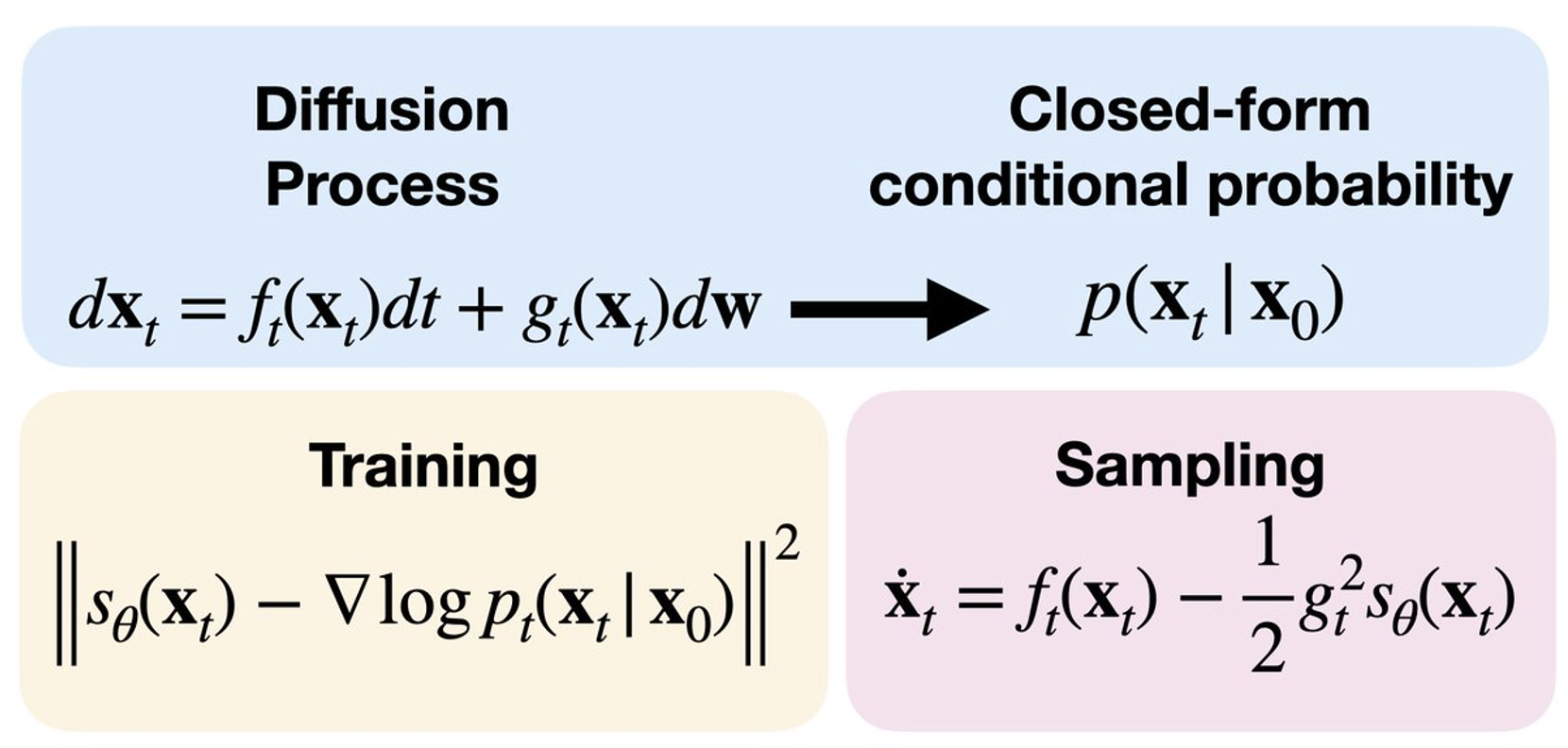
It would be relatively annoying if we would have to simulate the noising of the sample via an Euler-Maruyama approximation for every training point and then backpropagate through this. Instead, since we restrict ourselves to certain SDEs that have analytically known Gaussian transition densities, we can use closed-form transition densities to directly “jump” from data samples to an arbitrary time point t. This makes training score-based models much more efficient.
Image from this talk by Yaron Lipman. We can formulate score matching in terms of conditional transition densities for which we have closed-form solutions. We can then use these closed-form solutions to directly “jump” from data samples to an arbitrary time point t.
“Wait”, you may say at this point, “the score matching loss involving the conditional properties in this picture is different to the one we talked about before! How do I know they actually are the same?” You are right, this is not directly obvious! There is no reason to believe a priori that minimising E[∥∥∇xlnpt∣0(Xt∣X0)−sθ(t,Xt)∥∥2] is the same as minimising Et∈U(0,T)Ept(x)[∥∇xlogpt(x,t)−sθ(x,t)∥22].
The optimal predictor of X as a function of Y (Hilbert projection)
f∗(Y)=f−ismeasurableargminE[(X−f(Y))2]
is given by the conditional expectation
f∗(Y)=E(X∣Y)
For the case of martingales, we can show that the optimal predictor of the future as a function of the past in a martingale is given by the past itself: f∗(t,x)=s−ismeasurableargminE[(Xt+δ−f(Xt))2]//=Xt=E(Xt+δ∣Xt)
We can then use this fundamental property to show that minimising the MSE between our model estimate and the score function is equivalent to minimising the MSE between our model estimate and the conditional score function: sθ∗(t,x)=s−ismeasurableargminE[∫0T∥∥∇xlnpt∣0(Xt∣X0)−sθ(t,Xt)∥∥2dt]∣conditional expectation property=EX0∣Xt[∇xlnpt∣0(Xt∣X0)∣Xt=x]∣def. of expectation=∫p0∣t(x0∣x)∇xlnpt∣0(x∣x0)dx0∣Bayes=∫pt(x)pt∣0(x∣x0)p0(x0)∇xlnpt∣0(x∣x0)dx0∣log-deriv. trick=pt(x)1∫p0(x0)∇xpt∣0(x∣x0)dx0∣dom. convergence theorem=pt(x)1∇x∫p0(x0)pt∣0(x∣x0)dx0∣marginalise x0=pt(x)1∇xpt(x)∣log deriv. trick=∇xlnpt(x)
This derivation establishes that the minimizer of the conditional score matching objective equals the marginal score function. The same principle—that the conditional expectation minimizes mean squared error—will appear again when we discuss flow matching, showing the deep connection between these seemingly different training objectives.
4. Probability flow ODE
You saw that we used Langevin sampling-like techniques to simulate our reverse SDE. In Song et al. 2021, it was shown that you do not necessarily need to do that; instead of modelling a stochastic process, we can replace this backward diffusion process with its corresponding deterministic process (i.e. replace an SDE with an ODE) and still have the same marginal probability densities {pt(x)}t=0T. This is known as the probability flow ODE.
Definition: Every stochastic process described by an SDE has a corresponding deterministic process described by an ODE that has the same marginal probability densities {pt(x)}t=0T. This process is called the probability flow ODE. For a general SDE of the form dXt=μ(Xt,t)dt+σ(Xt,t)dWt, the corresponding ODE is given by
For the example of the backward SDE dXt=[μ(Xt,t)−σ2(t)∇xlogpt(Xt)]dt+σ(t)dWˉt (where we assume a scalar diffusion term with no dependency on Xt), the corresponding ODE is given by dXt=[μ(Xt,t)−21σ2(t)∇xlogpt(Xt)]dt
Looking at it, the ODE looks very similar to the SDE, but with the stochastic term dWˉt removed and an additional factor of 21 in front of the diffusion term. This is not a coincidence, but a direct consequence of the fact that the SDE and ODE have the same marginal probability densities. Let us look at the derivation for this.
Let’s start again with our general SDE dx=μ(x,t)dt+σ(x,t)dWt, where we assume σ(x,t) to be matrix-valued and dependent on x. We know that the Focker-Planck Equation of this general SDE is given by ∂t∂pt(x)=−∂x∂[μ(x,t)pt(x)]+∂x∂∂x∂[21σ(x,t)σ(x,t)Tpt(x)]
where pt(x) is the probability density of the SDE at time t.
We can now use the product rule to split the second term on the RHS into two terms: ∂t∂pt(x)=−∂x∂[μ(x,t)pt(x)]+21∂x∂[∇x[σ(x,t)σ(x,t)T]pt(x)]+21∂x∂[σ(x,t)σ(x,t)T∂x∂pt(x)]
Using the log-derivative trick to rewrite the last term, we get ∂t∂pt(x)=−∂x∂[μ(x,t)pt(x)]+21∂x∂[∇x[σ(x,t)σ(x,t)T]pt(x)]+21∂x∂[σ(x,t)σ(x,t)Tpt(x)∇xlogpt(x)]
Pulling the pt(x) and the ∂x∂ outside the whole expression, we get ∂t∂pt(x)=−∂x∂pt(x)[μ(x,t)−21∇x[σ(x,t)σ(x,t)T]−21σ(x,t)σ(x,t)T∇x[logpt(x)]]
If we now define the term in brackets on the RHS as μ~(x,t)pt(x), we get ∂t∂pt(x)=−∂x∂μ~(x,t)pt(x)
Looking at this equation, it looks again like a FPE, but for an SDE with a diffusion term σ~(x,t)=0. In that case, the FPE is also known as the Liouville equation and describes the evolution of the probability density of a deterministic process (i.e. an ODE) of the form dx=μ~(x,t)dt
Via this reasoning, we showed that the SDE and the probability flow ODE have the same marginal probability densities.
If we assume that the diffusion term does not depend on x, the derivative of the diffusion term ∇x[σ(x,t)σ(x,t)T] is zero. If we assume in addition that the diffusion term is scalar, the term 21σ(x,t)σ(x,t)T simplifies to 21σ2(t) and we get the probability flow ODE discussed before.
5. Flow Matching
We just saw that we can replace the stochastic process of the reverse SDE with a deterministic process that has the same marginal probability densities. An interesting question follows: if we can replace the reverse process with a deterministic process, can we also replace the forward process with a deterministic process and just train the whole model deterministically? This is exactly what Flow Matching does. To understand where it comes from, we first need to look at a class of models called continuous normalising flows.
5.1 Continuous normalising flows (CNFs)
Continuous Normalising Flows (CNFs) are a class of generative models that learn to transform a simple base distribution (typically a standard Gaussian) into a complex data distribution through a continuous-time flow. Unlike discrete normalising flows that use a finite sequence of transformations, CNFs model the transformation as a continuous process described by an ordinary differential equation (ODE).
The key idea is to define a vector field vθ(x,t) parameterized by a neural network that describes how points move through space over time. Given an initial point z0∼p0 (the base distribution), we can generate a sample z1 from the data distribution p1 by solving the ODE: dtdzt=vθ(zt,t)
where zt flows from t=0 to t=1. The change of variables formula for continuous flows gives us the log-probability of the transformed sample: logp1(z1)=logp0(z0)−∫01div(vθ(zt,t))dt
where div(vθ)=∑i∂xi∂vθi is the divergence of the vector field. This allows us to compute likelihoods and train the model via maximum likelihood estimation.
The main challenge with training CNFs is that computing the likelihood requires solving the ODE forward in time and computing the divergence, which can be computationally expensive. Flow Matching addresses this by providing a simulation-free training objective that avoids having to solve the ODE during training.
The key insight of Flow Matching is to define a conditional flow that directly connects a data point x1∼p1 to a noise point x0∼p0. Specifically, we define a conditional probability path pt(x∣x1) that interpolates between p0 and p1, and a corresponding conditional vector field ut(x∣x1) that generates this path.
For example, a simple linear interpolation path is: pt(x∣x1)=N(x∣(1−t)x0+tx1,σt2)
where x0∼p0 and x1 is a data sample. The corresponding conditional vector field that generates this path is: ut(x∣x1)=1−tx1−x0
The Flow Matching objective trains a neural network vθ(x,t) to match this conditional vector field: LCFM(θ)=Et,x1,x0[∥vθ(xt,t)−ut(xt∣x1)∥2]
where xt∼pt(x∣x1). This is called Conditional Flow Matching (CFM).
The remarkable result, shown in Lipman et al. 2023 and more recently in Tong et al. 2024, is that minimizing the conditional flow matching objective is equivalent to minimizing the marginal flow matching objective: LMFM(θ)=Et,xt∼pt[∥vθ(xt,t)−ut(xt)∥2]
where ut(x)=Ex1∣xt[ut(x∣x1)] is the marginal vector field.
The Same Principle as Score Matching: This equivalence holds because of the same fundamental property we used earlier for score matching: the conditional expectation minimizes the mean squared error. This is not a coincidence—both score matching and flow matching rely on this same mathematical principle, which we now apply to vector fields instead of score functions.
We can show this equivalence by expanding the marginal flow matching objective and applying the conditional expectation property: LMFM(θ)=Et,xt∼pt[∥vθ(xt,t)−ut(xt)∥2]=Et,xt∼pt[∥vθ(xt,t)−Ex1∣xt[ut(xt∣x1)]∥2]=Et,xt,x1∣xt[∥vθ(xt,t)−ut(xt∣x1)∥2]−Varx1∣xt[ut(xt∣x1)]
The variance term does not depend on θ, so minimizing LMFM(θ) is equivalent to minimizing: Et,xt,x1∣xt[∥vθ(xt,t)−ut(xt∣x1)∥2]=Et,x1,x0,xt∣x1[∥vθ(xt,t)−ut(xt∣x1)∥2]=LCFM(θ)
This shows that conditional and marginal flow matching minimize the same objective (up to a constant independent of θ).
Unified View: Both score matching and flow matching use the same mathematical principle:
Score Matching: The minimizer of E[∥∇xlogpt(xt∣x1)−sθ(xt,t)∥2] equals Ex1∣xt[∇xlogpt(xt∣x1)]=∇xlogpt(xt)
Flow Matching: The minimizer of E[∥ut(xt∣x1)−vθ(xt,t)∥2] equals Ex1∣xt[ut(xt∣x1)]=ut(xt)
In both cases, we can train using conditional objectives (which are easier to compute) while learning the correct marginal quantities. This unified perspective explains why both methods work and why they share similar training dynamics.
5.3 Comparison to score-based models
Flow matching and score-based diffusion models are closely related but differ in their formulation. Score-based models learn the score function ∇xlogpt(x) and use stochastic reverse SDEs for sampling, while flow matching learns a vector field vθ(x,t) and uses deterministic ODEs.
The key connection is that the probability flow ODE we derived earlier can be written in terms of the score function: dtdXt=μ(Xt,t)−21σ2(t)∇xlogpt(Xt)
If we set μ=0 and σ2(t)=1, this becomes: dtdXt=−21∇xlogpt(Xt)
which is exactly a flow matching ODE with vector field vθ(x,t)=−21sθ(x,t) where sθ is the learned score function.
The main advantages of flow matching over score-based models are:
Deterministic sampling: Flow matching uses ODEs instead of SDEs, leading to deterministic and often faster sampling
Direct training: Flow matching directly optimizes the vector field without needing to learn score functions
Flexibility: Flow matching allows for more flexible probability paths beyond the diffusion process
5.4 Stochastic Interpolants - Unifying stochastic and deterministic generative models
You saw that despite the setup for CNFs and score-based models being quite different at the start, their final solutions are quite similar. Recently, people tried to formalise this connection more explicitly and unify the two approaches. One example of such an effort is the work on Stochastic Interpolants by Michael Albergo and others (here a talk where they present the work).
Stochastic interpolants provide a unified framework that encompasses both deterministic flow-based models and stochastic diffusion models. The key idea is to define a stochastic process that interpolates between two distributions p0 and p1.
Definition (Stochastic Interpolant): A stochastic interpolant is a process Xt defined for t∈[0,1] that satisfies: Xt=αtX0+βtX1+γtZ
where:
X0∼p0 (initial distribution, e.g., data)
X1∼p1 (target distribution, e.g., noise)
Z∼N(0,I) is an independent Gaussian noise
αt,βt,γt are time-dependent coefficients
The coefficients are chosen such that:
α0=1,β0=0,γ0=0 (so X0∼p0)
α1=0,β1=1,γ1=0 (so X1∼p1)
αt2+βt2+γt2=1 (for normalization)
A common choice is the variance-preserving interpolant:
αt=1−t
βt=t
γt=t(1−t)
This gives: Xt=1−tX0+tX1+t(1−t)Z
The Interpolant SDE: The stochastic interpolant Xt satisfies an SDE of the form: dXt=bt(Xt)dt+σtdWt
where the drift bt(x) and diffusion σt can be derived from the interpolant definition. Specifically, if we take the time derivative of the interpolant and use Itô’s lemma, we get: bt(x)=α˙tE[X0∣Xt=x]+β˙tE[X1∣Xt=x]+γ˙tE[Z∣Xt=x]
and σt=γ˙t.
The Interpolant ODE: The stochastic interpolant also has a corresponding deterministic ODE (the probability flow ODE) that preserves the same marginal distributions: dtdXt=bt(Xt)−21σt2∇xlogpt(Xt)
This unifies the stochastic (SDE) and deterministic (ODE) perspectives.
Training Objective: To train a model using stochastic interpolants, we learn a vector field vθ(x,t) that approximates either:
The drift bt(x) for the SDE formulation, or
The velocity field bt(x)−21σt2∇xlogpt(x) for the ODE formulation
The training objective is similar to flow matching: L(θ)=Et,X0,X1,Z[∥vθ(Xt,t)−ut(Xt∣X0,X1,Z)∥2]
where ut(x∣x0,x1,z) is the conditional velocity field that can be computed analytically from the interpolant definition.
Connection to Flow Matching and Score Matching:
Flow Matching: If we set γt=0 (no stochastic component), the interpolant becomes deterministic and reduces to flow matching.
Score Matching: The score function appears naturally in the probability flow ODE: ∇xlogpt(x)=σt22(bt(x)−vt(x)), where vt is the velocity field of the ODE.
Diffusion Models: Standard diffusion models (like DDPM) correspond to specific choices of the interpolant coefficients, typically with αt=αˉt, βt=1−αˉt, and γt=0.
This unified framework shows that flow matching, score matching, and diffusion models are all special cases of stochastic interpolants, differing only in their choice of interpolation path and whether they use the stochastic (SDE) or deterministic (ODE) formulation.